This Python program removes duplicates from a list by converting the list to a set, which automatically removes duplicate elements, and then converting the set back to a list.
In Python, a list is a collection of elements that can contain duplicate values. Removing duplicates from a list involves eliminating repeated elements, so that each element appears only once in the modified list. This can be useful for various tasks like data cleaning and ensuring uniqueness in a dataset.
Problem statement
You are given a list of elements. Your task is to write a Python program to remove duplicates from the list while preserving the original order of elements. Create a function that takes the input list and returns a new list with duplicates removed.
Python Program to Remove Duplicates from a List
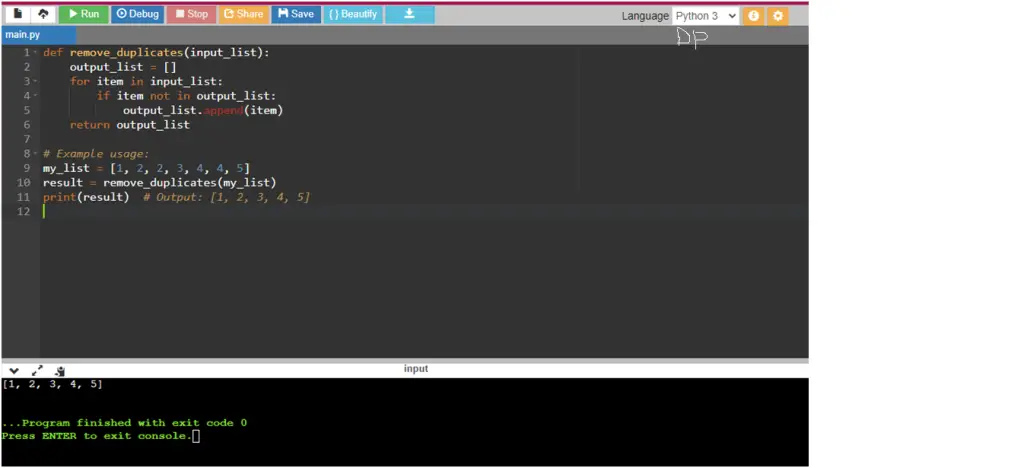
def remove_duplicates(input_list):
output_list = []
for item in input_list:
if item not in output_list:
output_list.append(item)
return output_list
# Example usage:
my_list = [1, 2, 2, 3, 4, 4, 5]
result = remove_duplicates(my_list)
print(result) # Output: [1, 2, 3, 4, 5]
How it works
To understand how the program works, let’s break down the Python program step by step:
Code:
def remove_duplicates(input_list):
output_list = [] # Create an empty list to store unique elements
for item in input_list:
if item not in output_list:
output_list.append(item)
return output_list
- We define a function called
remove_duplicatesthat takes one argument,input_list, which is the list from which we want to remove duplicates. - We create an empty list called
output_listto store the unique elements. This will be the list where we build the result. - We use a
forloop to iterate through each item in theinput_list. This loop examines each element one by one. - For each element in the
input_list, we check whether it’s already in theoutput_list. We do this using theif item not in output_listcondition. This condition checks if the current item is not already present in theoutput_list. - If the condition is met (i.e., the item is not in
output_list), we append it to theoutput_listusingoutput_list.append(item). This ensures that only unique elements get added to theoutput_list. - We continue this process for all elements in the
input_list, and theoutput_listgradually accumulates unique elements in the order they appear in theinput_list. - Finally, we return the
output_list, which now contains all the unique elements from theinput_listwhile preserving their original order.
Here’s how the example usage works:
Code:
my_list = [1, 2, 2, 3, 4, 4, 5]
result = remove_duplicates(my_list)
print(result) # Output: [1, 2, 3, 4, 5]
- The
my_listcontains duplicates:[1, 2, 2, 3, 4, 4, 5]. - When we call
remove_duplicates(my_list), it processes each element in the order it appears. - It creates a new list
output_listand adds elements to it only if they are not already present. - After processing all elements, it returns the
output_list, which contains unique elements in the original order:[1, 2, 3, 4, 5].
This is how the program works to remove duplicates from a list while preserving the original order of elements.
Input/Output