This C program removes all repeated words in a given string. It prompts the user to enter a string, processes the string, and removes any duplicate occurrences of words. Finally, it displays the modified string with all repeated words removed.
Problem Statement
Write a C program to delete all repeated words in a given string.
The program should perform the following tasks:
- Prompt the user to enter a string.
- Tokenize the input string into individual words using space as the delimiter.
- Convert all words to lowercase for case-insensitive comparison.
- Identify and remove any duplicate occurrences of words, keeping only the first occurrence.
- Print the modified string with repeated words removed.
Assumptions:
- The input string contains only alphabetic characters and spaces.
- The maximum length of the input string is 100 characters.
- The maximum length of a single word in the string is 100 characters.
This problem statement provides a clear description of the task that the program needs to accomplish. It outlines the required steps and specifications for the program to successfully delete repeated words in a string. It also provides an example of input and output to illustrate the expected behavior of the program.
C Program to Delete All Repeated Words in String
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#define MAX_LENGTH 100
void removeRepeatedWords(char* str) {
char words[MAX_LENGTH][MAX_LENGTH];
int count[MAX_LENGTH] = {0};
int numWords = 0;
int i, j, k;
// Tokenize the input string into words
char* token = strtok(str, " ");
while (token != NULL) {
strcpy(words[numWords], token);
numWords++;
token = strtok(NULL, " ");
}
// Convert all words to lowercase for case-insensitive comparison
for (i = 0; i < numWords; i++) {
for (j = 0; j < strlen(words[i]); j++) {
words[i][j] = tolower(words[i][j]);
}
}
// Count the occurrences of each word
for (i = 0; i < numWords; i++) {
if (count[i] == 0) {
count[i] = 1;
for (j = i + 1; j < numWords; j++) {
if (strcmp(words[i], words[j]) == 0) {
count[i]++;
count[j] = -1;
}
}
}
}
// Remove repeated words from the string
int removed = 0;
for (i = 0; i < numWords; i++) {
if (count[i] == 1) {
if (removed > 0) {
printf(" ");
}
printf("%s", words[i]);
removed++;
}
}
}
int main() {
char str[MAX_LENGTH];
printf("Enter a string: ");
fgets(str, MAX_LENGTH, stdin);
// Remove trailing newline character from fgets
if (str[strlen(str) - 1] == '\n') {
str[strlen(str) - 1] = '\0';
}
printf("Original string: %s\n", str);
printf("String with repeated words removed: ");
removeRepeatedWords(str);
printf("\n");
return 0;
}
How it Works?
- The program prompts the user to enter a string.
- The input string is tokenized into individual words using the space character as the delimiter. This is achieved using the strtok() function.
- Each word in the tokenized string is converted to lowercase using the tolower() function. This ensures case-insensitive comparison of words.
- The program creates two arrays:
wordsandcount. Thewordsarray stores the unique words from the input string, while thecountarray keeps track of the count of each word. - The program iterates through each word in the
wordsarray. For each word, it compares it with all subsequent words to check for duplicates. If a duplicate is found, the count of the duplicate word is incremented, and the count of the original word is set to -1 to mark it for removal. - After identifying the repeated words, the program prints the modified string by only including words with a count of 1. It skips the words with a count of -1, which were marked as duplicates.
- The program terminates.
The program effectively removes repeated words by tokenizing the input string, converting words to lowercase for case-insensitive comparison, and keeping track of the count of each word. By printing only the words with a count of 1, the program generates the modified string with repeated words removed while preserving the order of non-repeated words.
Input / Output
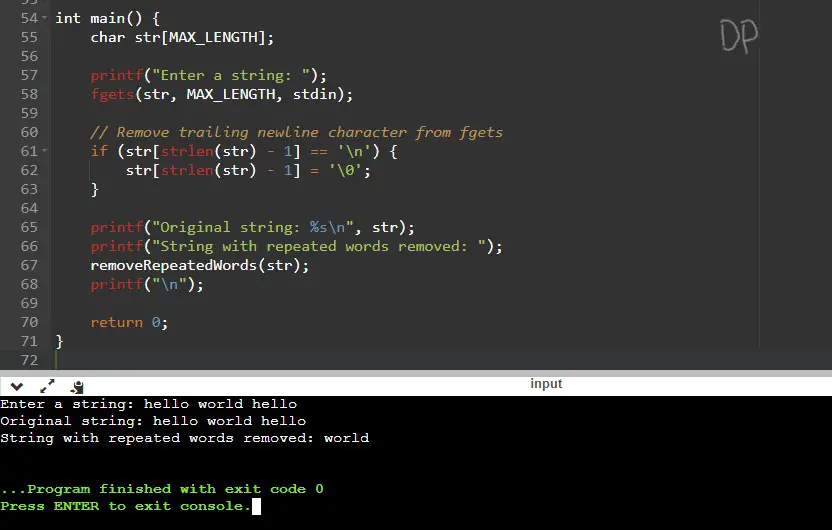
In the input, we enter the string “hello world hello”. The program then removes the repeated words and prints the modified string as “world”. The program is case-insensitive, so it treats “hello” and “Hello” as the same word. It also preserves the original case of the words when printing the modified string.